








سیستم ذخیره سازی هدوپ
Hadoop چیست؟
هدوپ یک نرم افزار متن باز تحت لیسانس آپاچی است که با جاوا برنامه نویسی شده و برای تقسیم بندی و توزیع فایل های متمرکز به کار می رود. هدف از پروژه Hadoop توسعه نرم افزاری متن باز برای انجام محاسبات مطمئن، مقیاس پذیر و توزیع شده می باشد. نرم افزار Hadoop یک چارچوب است که امکان پردازش توزیع شده مجموعه ای از داده های حجیم را فراهم می آورد و این عملیات توسط یک مدل برنامه نویسی ساده بر روی سیستم clustering انجام میگیرد.طراحی آن به شکلی است که میتواند بر روی یک یا هزاران سرور محاسبات یا عملیات ذخیره سازی اطلاعات را به شکلی محلی انجام دهد. به جای تکیه بر سخت افزار، کتابخانه این نرم افزار هرگونه شکست را در لایه Application تشخیص و برطرف میکند، بنابراین سرویس موردنظر با قابلیت اطمینان بسیار بالایی بر روی سیستم clustering تعدادی سخت افزار ارائه میگردد که هرکدام میتواند منجر به شکست شود.ایده اولیه هدوپ اولین بار در شرکت گوگل رقم خورد اما خیلی ها باور به پیاده سازی این سیستم نداشتند و در چند سال اول این ایده تنها بصورت تئوری مطرح بود این شرکت در پی افزایش حجم تبادل اطلاعات، به دنبال راه حلی برای افزایش سرعت و راندمان سرورهای خود بود که سیستم توزیع منحصر به فردی برای خود ابداع کرد به نامGFS Google File System و در پی این موفقیت، انجمن توزیعApache به فکر گسترش این تکنولوژی در سطح وسیعتری افتاد و سیستم هدوپ به وجود آمد. کلودرا شرکتی است که بصورت فعال در این زمینه فعال می باشد و بسته نرم افزاری بی نظیر هدوپ را ایجاد کرده و آن را انتشار داده و پشتیبانی می کند.
ساختار کلی اطلاعاتی در هدوپ بدینگونه می باشد که اطلاعات توسط سیستم هدوپ شکسته شده و به چندین سرور فرستاده می شود.سرورها بسته به نوع اطلاعات که ممکن است پردازشی یا ذخیره ای باشد اطلاعات را پردازش یا ذخیره سازی می کنند. در هنگام در خواست اطلاعات مجدد سیستم اطلاعات را از سرور های مختلف گرفته ، مونتاژ کرده و در خروجی نمایش می دهد.
خوبی این سیستم تهیه نسخه پشتیبان از اطلاعات بصورت خودکار است. هر تکه از اطلاعات در چندین قسمت سرور ذخیره می شود و در صورت آسیب دیدن یکی از سرورها ، سرور دیگر قادر است مسئولیت را بر عهده گرفته و اطلاعات مورد نظر را جایگزین کند.
Apache Hadoop از چه قسمت هایی تشکیل شده است؟
Hadoopازچهار بخش زیر تشکیل گردیده است:
• Hadoop Common:امکاناتی برای پشتیبانی از ماژول های دیگر Hadoop
• Hadoop Distributed File System : سیستم توزیع شده فایل ها که دسترسی به داده های نرم افزار را با توان بالا فراهم میسازد.
•Hadoop YARN : چهارچوبی برای مدیریت Clustering
• HadoopMapReduce :سیستمی برای پردازش موازی از مجموعه داده های بزرگ
Hadoop چگونه عمل می کند؟
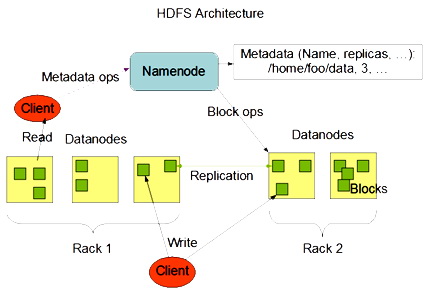
سیستم بدین صورت عمل میکند که اطلاعات دریافت شده به صورت بلوک های ۶۴ مگابایتی در آمده و هر تکه در یک سرور جداگانه ذخیره می شود. در تصویر زیر سرورNamenodeدر واقع همان سرور اصلی (Master) می باشد که وظیفه ی کنترل سرورهای دیگر (Slave) را به عهده دارد. بخشMap Reduce نیز بر روی سرور اصلی اجرا می شود و بخشHDFS یا همانHadoop Distributed File System بر روی سرورهای جانبی اجرا می شود. سرورهای جانبی وظیفه ی ذخیره سازی اطلاعات را بر روی هارد دیسک های خود به عهده دارند. یعنی زمانی که کاربر درخواست فراخوانی یک فایل را صادر می کند، سرور اصلی از طریق آدرس هایی که در اختیار دارد، بلوک های مورد نظر را از سرورهای مختلف فراخوانی کرده و پس از سر هم کردن و تکمیل کردن فایل، آن را به کاربر تحویل می دهد.
نکته ی جالب پروسه مربوط بهData Replication می شود. الگوریتم این برنامه طوری نوشته شده است که چندین نسخه کپی از بلاک ها بر روی دیگر سرور ها قرار می گیرد و این امر دو مزیت بزرگ دارد: اول این که شبکه در مقابل خطاهای سخت افزاری از قبیل سوختن هارد دیسک، اشکالات سخت افزاری سرورها و … در امان میباشد و در صورتی که هر یک از سرورها به دلایلی از شبکه خارج شوند، اطلاعات مورد نظر از روی سرورهای دیگر فراخوانی می شوند. مزیت دوم این قابلیت این است که دیگر نیازی به استفاده از تکنولوژیRAID نمیباشد و می توان از حداکثر فضای هارد دیسک های خود استفاده نمود.
مزایای استفادهHadoop :
•دسترسپذیراست: هدوپ روی کلاسترهای بزرگ تشکیل شده از سرورهای معمولی (در دسترس) یا روی سرویسهای رایانش ابری همچون سرویسEC2 آمازون اجرا میشود.
•مقاوم است:Hadoopبر روی سختافزارهایی معمولی اجرا میشود و به راحتی از عهده خرابی گرهها بر میآید. زیرا فرض میکند که عناصر رایانشی و ذخیرهسازی از کار خواهند افتاد، بنابرایم چندین کپی از دادهای که روی آن دارد کار میکند را نگه میدارد تا اطمینان حاصل کند که پردازش میتواند باز توزیع شود.
• مقیاسپذیر است:Hadoopهمچنان که حجم دادهها افزایش مییابد با افزودن گرههای جدید به کلاستر به صورت خطی گسترش مییابد و با این کار اجازه عملیات روی هزاران گیگابایت از دادهها را میدهد.
• ساده است:Hadoopبه کاربران این اجازه را میدهد که به سرعت کًدهای موازی کارا بنویسند.
• مقرون به صرفه است :Hadoopمحاسبات موازی انبوه را در سرورها امکان پذیر میسازد. در نتیجه کاهش قابل ملاحظه ای در هزینه هر ترابایت ذخیره سازی را با خود به همراه دارد و به نوبه خود باعث می شود آن را مقرون به صرفه نماید.
• انعطاف پذیر است:Hadoopبر خلاف ظاهر ساده خود هر نوع و فرمتی از اطلاعات را میتواند از منابع مختلف به خود جذب کند.داده ها از منابع مختلف میتوانند در کنار یکدیگر قرار گرفته و در نتیجه تجزیه و تحلیل بهتری بر روی آن ها انجام خواهد پذیرفت
• دارای تحمل پذیری بالای خطاها:هنگامی که یک نود در مدار از دست برود سیستم تغییرمسیرداده وادامه کار را با مسیر دوم دیتا ادامه خواهد داد و پردازش بدون از دست دادن زمان ادامه می یابد

مائده مستوفی راد شرکت عصر ارتباطات و انتقال داده های سپاهان














